
Le contexte
Au cours de nos nombreux onboarding clients, nous avons conduit de nombreux projets de mise en place ou de migration du registre des traitements. Lorsque nous débutons un projet de migration de l'existant, nous réunissons bien souvent les parties prenantes du projet de conformité : RSSI, DPO, Responsable des risques, CDO... Systématiquement, une question se pose : comment aborder la conception des fiches de traitement de la bonne façon ?
En effets, les utilisateurs se posent régulièrement des questions sur la bonne approche pour créer les fiches de traitement : quelle granularité, une ou plusieurs finalités ? quelle définition du traitement, comment s'assurer que ce qui est déclaré est bien réel ? En effet le concept de traitement de données est très abstrait et peut être interprété de différentes manières !
Même si l'objectif principal de cette démarche n'est pas d'éviter les sanctions, il faut avoir en tête que très régulièrement, des entreprises sont sanctionnées par les autorités de contrôle car elles n'ont pas réellement appliqué ce qui est déclaré dans le registre, c'est par exemple le cas de Discord, sanctionné à hauteur de 800 000 €
Tout l'enjeu de cet exercice se trouve ici : il faut trouver une méthode qui permet de réconcilier le légal (les documents juridiques, le registre des traitements, les DPA...) et la réalité du terrain (des procédures, du code, des bases de données...) !
Fort de toutes ces expériences, nous avons identifié deux grandes méthodologies de conception du registre. Nous avons pensé qu'il serait intéressant de vous les présenter, car chacune d'elle présente des forces et des faiblesses, même si on ne va pas vous le cacher, il y en a une que nous préférons🙊 !
Méthode n° 1 : l'approche Top-down
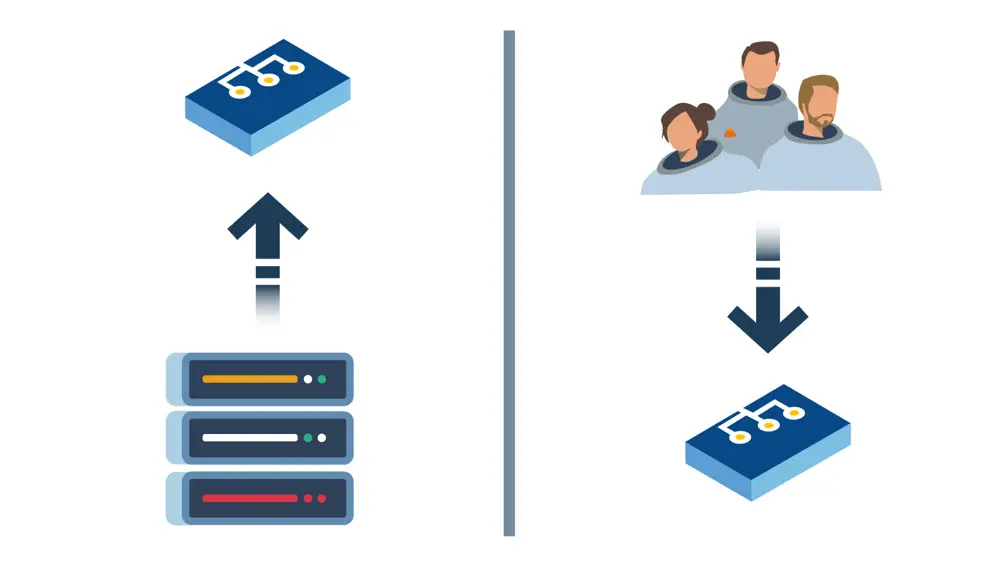
C'est la méthodologie la plus répandue chez nos clients. C'est la plus classique pour les utilisateurs ayant une parcours juridique, une organisation de complexité faible ou moyenne et qui traite des volumes de données faibles. On peut également la qualifier de "méthode descendante". Le principe est très simple : le DPO va construire des activités de traitement pour ensuite collecter les informations sur les données personnelles, personnes concernées...
On part des usages pour déterminer les données.
Le processus peut se résumer de cette façon :
Inventaire des traitements : cette phase consiste à lister l'ensemble des traitements de données à caractère personnel de votre organisation. Cela peut se faire en effectuant des ateliers avec les personnes de différents services ou filiales de l'organisation. On organise un atelier de type brainstorming qui permet d'établir une première liste d'usage de données qu'il faudra éventuellement dégrossir ou raffiner par la suite. La difficulté sera de choisir la bonne granularité pour vos traitements:
- un traitement par finalité : cela limite considérablement la quantité d'information à renseigner. C'est un modèle préconisé par l'autorité de contrôle anglais (ICO).
- Un traitement avec plusieurs finalités (une principale et des finalités secondaires) : ce modèle est préconisé par la CNIL
Collecte d'informations : cette phase peut s'avérer fastidieuse. Elle va souvent nécessiter au responsable du projet de partir à une véritable chasse aux informations par le biais de questionnaires, d'ateliers... Cette collecte doit permettre de renseigner l'ensemble de ces informations :
- Les catégories de données personnelles : l'inventaire des données est dans ce cas très simple, vous déterminez une liste de catégories de données type et vous renseignez ces catégories avec leurs durées de conservation.
- La collecte des destinataires et transferts de données.
- La collecte des informations sur les mesures de sécurité.
Finalisation: l'ensemble des informations du traitements sont validées par le Data Protection Officer (DPO). Un PIA est effectué si nécessaire et le cycle de vie du traitement se poursuit avec une revue régulière dans le cas de révisions ou de changement de sous-traitant.
Cette méthode, plus verticale, a la grande force d'être la plus simple et rapide à mettre en place pour les personnes ayant un bon bagage juridique.
Méthode n° 2 : l'approche Bottom-up
Cette méthodologie est moins fréquemment utilisée par l'ensemble de nos clients mais plus en vogue dans les startup ou les sociétés qui ont une culture de la donnée très forte. Cette approche est plus vertueuse sur le long terme mais apporte également un certain nombre de contraintes.
L'objectif est ici de partir de la donnée pour en décliner l'usage.
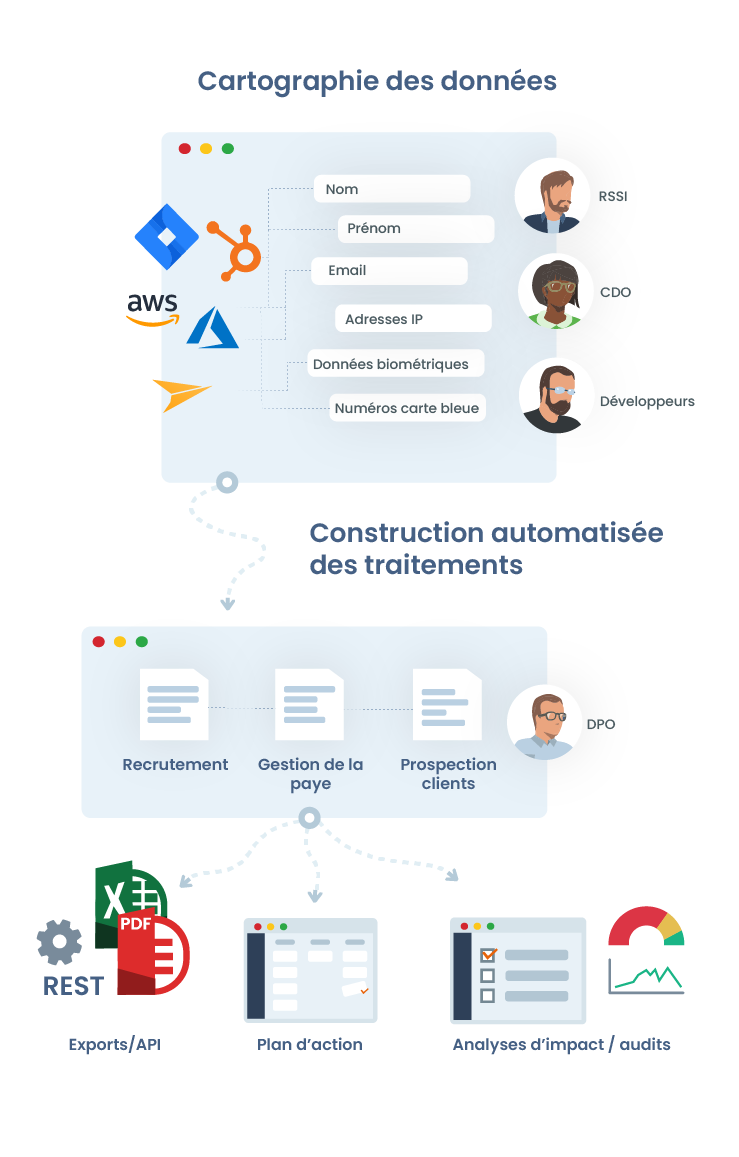
Cartographie des données :
- Cartographie des actifs logiciels : un actif est une entité autonome de votre système d'information, cela peut être un serveur, un logiciel, un bâtiment, une ressource sur le cloud... Pour cette phase, vous pouvez vous baser sur l'analyse du DPA (Data processing agreement) qui est un document légal que vous devez signer avec vos sous-traitants. Celui-ci regorge d'informations sur la nature des données traitées par l'éventuel sous-traitant.
- Inventaire des données au sein de chaque actif avec le détail des champs et leurs durées de conservation associées (En base active, archivage intermédiaire...).
- Identification du sous-traitant associé (si il y en a un). Bien souvent il s'agit de la société qui va éditer le logiciel.
- L'inventaire des mesures mises en œuvre pour sécuriser cet actif
Mise en place du ou des traitements en se basant sur un ou plusieurs actifs logiciel. Exemple : à partir de l'actif "Salesforce" avec les données qui contient le profil du client potentiel (email, téléphone...), je déduis l'existence d'un traitement de données de "Prospection commerciale"
Finalisation : le traitement est validé par le DPO et un PIA est effectué dessus si nécessaire. Dans le cas d'une modification d'un actif (un changement dans le DPA par exemple), on commencera toujours par la modification des informations renseignées au niveau de l'actif pour ensuite mettre à jour les traitement concernés.
La grande force de cette méthode est sa nature plus opérationnelle et plus proche de la réalité du terrain pour ceux qui ne sont pas issus du milieu juridique. Elle est souvent très appréciée par les membres de l'équipe privacy qui ont un background technique (RSSI, CDO...).
La nature déclarative et complexe de la mise en place de la cartographie peut sembler déroutante au premier abord. Mais c'est un travail qui peut se mener très efficacement si les opérationnels qui gèrent les données sont impliqués dans le projet suffisamment tôt.
Ces ateliers sont d'ailleurs bien souvent l'occasion d'identifier certaines mauvaises pratiques ou vulnérabilité auxquelles il faut remédier. La grande vertu de la méthode bottom-up c'est qu'elle encourage grandement le principe de minimisation des données personnelles.
La phase de cartographie, si elle est incorrectement exécutée, peut s'avérer très complexe pour les opérationnels et peut devenir un véritable gouffre en temps et en argent. C'est pourquoi il est fortement recommandé d'utiliser des outils comme Dastra qui vous permettent de structurer, tenir et partager cet inventaire de manière collaborative et totalement intégrée (connecteurs, API...).
Avec le bon outil, cela se révèle être plus intuitif et rapide car presque toutes les informations sont présentes dans la cartographie et ont juste besoin d'être synchronisées avec le registre des traitements. Votre registre reflète alors ce qui se passe réellement dans votre système d'information !
Nous mêmes chez Dastra, nous utilisons activement la cartographie de données pour concevoir notre registre. C'est devenu un outil incontournable qui va même bien plus loin que la constitution du registre: c'est désormais l'outil de pilotage des actifs internes de la société. En voici un petit extrait : 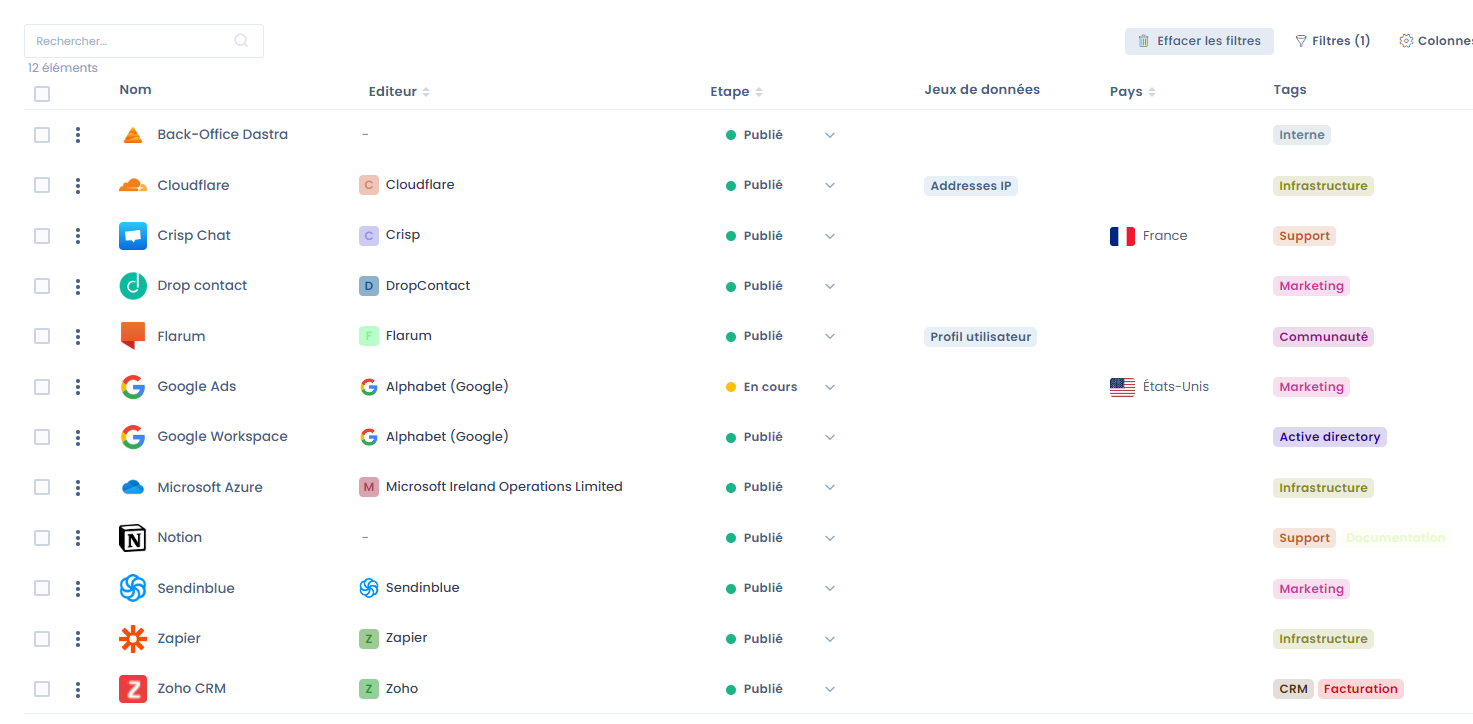
Doit-on faire de la cartographie automatisée ?
La cartographie automatisée (ou Data Discovery) consiste à utiliser des connecteurs qui vont automatiquement récupérer les listing des données concernées dans les actifs (logiciel SaaS, base de données...). Cette approche peut paraître très séduisante au premier abord et peut très bien fonctionner pour certaines structures (startups, pme avec infra cloud...).
Chez Dastra, nous avons la conviction que la technologie facilitera grandement ce travail. Cependant, dans la pratique, cela s'avère bien souvent plus chronophage, car cela nécessite de disposer de toutes les informations nécessaires à l'établissement des connecteurs et de mobiliser un grand nombre de personnes sur le sujet (DSI, Dev...). Tout cela pour collecter un volume d'informations très souvent peu important : la nature des données traitées dans un logiciel.
D'autre part, les données collectées par la cartographie automatisée ne représentent qu'une infime partie de ce qui doit être renseigné au sein du registre : une liste de jeux de données plus ou moins bien catégorisés avec les types de champs détaillés avec un niveau de sensibilité.
Un nettoyage est bien souvent nécessaire pour rendre les données digestes et compréhensible pour le commun des mortels. Malheureusement aujourd'hui, il est très difficile pour ces outils de récupérer d'autres informations telles que les mesures de sécurité, les durées de conservation, les personnes concernées...
Chez Dastra nous avons conduit plusieurs projets de cette nature qui se sont heurtés à de nombreux freins car ils étaient surdimensionnés techniquement par rapport au besoin qui est finalement très simple.
Nous sommes de toute façon convaincus que cette technologie ne se substitue pas à la richesse des interactions humaines autour du projet de conformité !
Comment choisir la bonne méthode ?
"Il n'y a pas de bonne ou de mauvaise méthodologie", Le choix de la méthode dépendra bien souvent des critères suivants :
- La taille de la société (nombre de salariés, filiales...)
- La culture de la donnée
- Les compétences de l'équipe privacy (juridique, sécurité, technique...)
- La gouvernance interne (organisation, disponibilité, délais...)
Le tableau de synthèse ci-dessous peut vous aider à choisir parmi ces deux méthodes
Tableau comparatif des deux approches
| Méthodologie | Cible | Bénéfices | Inconvénients |
|---|---|---|---|
| Top-Down (Descendante) | Petites organisations ou collectivités Entreprise avec une faible culture de la donnée Equipe légale avec une faible affinité pour l'IT | Rapidité de mise en place Moins de travail Correspond bien aux attentes légales du RGPD | Peut engendrer des difficultés si l'équipe de mise en place du registre ne connaît pas les données de l'organisation Plus contraignant pour les opérationnels L'inventaire des données sera beaucoup moins valorisable car modelé pour des attentes légales uniquement Plus complexe à maintenir sur le long terme |
| Bottom-Up (Ascendante) | Grandes ou moyennes organisations Avec une forte culture de la donnée Equipe légale avec forte affinité IT | Faire l'inventaire des données sera moins abstrait que de créer directement des traitements. Le registre reflète la réalité de l'organisation La tenue du registre sera plus aisée sur le long terme Plus de membres de l'organisation sont impliqués Création de fiche de traitement est plus automatisé | Globalement plus difficile et long à mettre en place Projet nécessitant une bonne gouvernance |
La meilleure approche, un mix des deux ?
Chez Dastra, nous aimons préconiser la solution de création du registre en Bottom-up qui est plus vertueuse sur le long terme, mais il y a bien souvent des objections à l'utilisation de cette méthode qui sont relevées par le client : "Mon traitement ne concerne que des données physiques ?", "Ce traitement ne peut pas se matérialiser par un actif logiciel ?". En effet, cette approche n'est pas compatible avec toutes les natures de traitement.
La meilleure approche se trouve probablement entre les deux : certains traitements qui relèvent de données physiques complexes à cartographier peuvent être conçus en Top-down, tandis que les traitement impliquant des actifs logiciels où les données sont facilement identifiables peuvent être traités en Bottom-up.
Ce qui est important est de bien identifier les enjeux autour du traitement. Dites vous que si le traitement doit faire l'objet d'une analyse d'impact, il faudra de toute façon le cartographier de manière très précise, alors autant aller directement sur la méthode Bottom Up ! Si votre traitement est très peu risqué pour les personnes concernées et votre activité, ne passez pas trop de temps dessus.
Considérez qu'il faut travailler en ayant l'approche par les risques demandée par le RGPD
Conclusion
Dastra a la force de répondre à ces deux approches parfaitement. Nous proposons nativement différentes options de création de fiche de traitement : 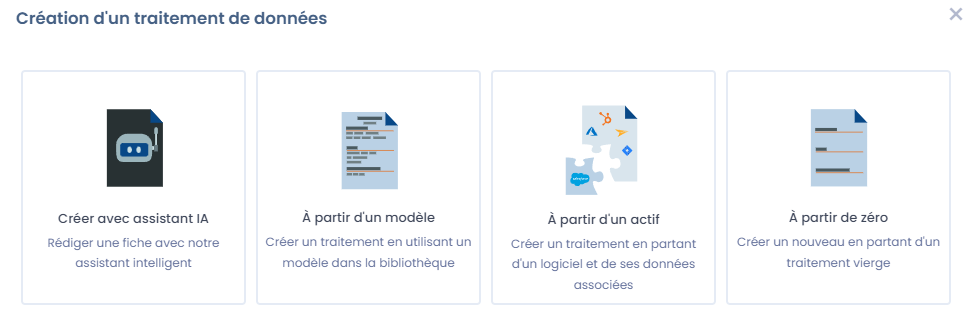 vous pouvez tout à fait concevoir vos fiches de traitements en mode Top-Down en créant une fiche de traitement à partir de notre bibliothèque de modèles ou en utilisant l'assistant IA. Vous pouvez ensuite la personnaliser et l'améliorer pour qu'elles soient cohérentes avec ce qui se passe réellement dans l'organisation.
vous pouvez tout à fait concevoir vos fiches de traitements en mode Top-Down en créant une fiche de traitement à partir de notre bibliothèque de modèles ou en utilisant l'assistant IA. Vous pouvez ensuite la personnaliser et l'améliorer pour qu'elles soient cohérentes avec ce qui se passe réellement dans l'organisation.
Si vous préférez le Bottom-up, partez sur notre outil de cartographie de données intégré et personnalisable. Tout est fait pour vous simplifier la vie au maximum. Vous pouvez également vous aider de notre assistant IA et nos modèles pour construire rapidement les fiches de logiciel avec les champs prédéfinis. Une fois la cartographie en place, générez vos fiches de traitement à partir de l'actif concerné par votre traitement. Dastra propose également des outils pour faire en sorte de garder les actifs synchronisés avec les traitements.
Chez Dastra, nous avons conçu à 100% notre registre en bottom-up, c'était l'approche la plus évidente pour nous étant donné notre background technique, la culture startup et les nombreux traitements qui concernent le marketing web...